 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of ADoBo at IberLEF 2025: Automatic Detection of Anglicisms in Spanish
Jul 29, 2025This paper summarizes the main findings of ADoBo 2025, the shared task on anglicism identification in Spanish proposed in the context of IberLEF 2025. Participants of ADoBo 2025 were asked to detect English lexical borrowings (or anglicisms) from a collection of Spanish journalistic texts. Five teams submitted their solutions for the test phase. Proposed systems included LLMs, deep learning models, Transformer-based models and rule-based systems. The results range from F1 scores of 0.17 to 0.99, which showcases the variability in performance different systems can have for this task.
Fully Bayesian Approaches to Topics over Time
Apr 21, 2025The Topics over Time (ToT) model captures thematic changes in timestamped datasets by explicitly modeling publication dates jointly with word co-occurrence patterns. However, ToT was not approached in a fully Bayesian fashion, a flaw that makes it susceptible to stability problems. To address this issue, we propose a fully Bayesian Topics over Time (BToT) model via the introduction of a conjugate prior to the Beta distribution. This prior acts as a regularization that prevents the online version of the algorithm from unstable updates when a topic is poorly represented in a mini-batch. The characteristics of this prior to the Beta distribution are studied here for the first time. Still, this model suffers from a difference in scale between the single-time observations and the multiplicity of words per document. A variation of BToT, Weighted Bayesian Topics over Time (WBToT), is proposed as a solution. In WBToT, publication dates are repeated a certain number of times per document, which balances the relative influence of words and timestamps along the inference process. We have tested our models on two datasets: a collection of over 200 years of US state-of-the-union (SOTU) addresses and a large-scale COVID-19 Twitter corpus of 10 million tweets. The results show that WBToT captures events better than Latent Dirichlet Allocation and other SOTA topic models like BERTopic: the median absolute deviation of the topic presence over time is reduced by $51\%$ and $34\%$, respectively. Our experiments also demonstrate the superior coherence of WBToT over BToT, which highlights the importance of balancing the time and word modalities. Finally, we illustrate the stability of the online optimization algorithm in WBToT, which allows the application of WBToT to problems that are intractable for standard ToT.
None of the Others: a General Technique to Distinguish Reasoning from Memorization in Multiple-Choice LLM Evaluation Benchmarks
Feb 18, 2025In LLM evaluations, reasoning is often distinguished from recall/memorization by performing numerical variations to math-oriented questions. Here we introduce a general variation method for multiple-choice questions that completely dissociates the correct answer from previously seen tokens or concepts, requiring LLMs to understand and reason (rather than memorizing) in order to answer correctly. Using this method, we evaluate state-of-the-art proprietary and open-source LLMs on two datasets available in English and Spanish: the public MMLU benchmark and the private UNED-Access 2024 dataset. Results show that all models experience remarkable accuracy drops under our proposed variation, with an average loss of 57% on MMLU and 50% on UNED-Access 2024, ranging from 10% to 93% across models. Notably, the most accurate model in our experimentation (OpenAI-o3-mini) is not the most robust (DeepSeek-R1-70B), suggesting that the best models in standard evaluations may not be the ones with better reasoning capabilities. Also, we see larger accuracy drops in public (vs private) datasets and questions posed in their original language (vs a manual translation), which are signs of contamination and also point to a relevant role of recall/memorization in current LLMs' answers.
Small Language Models can Outperform Humans in Short Creative Writing: A Study Comparing SLMs with Humans and LLMs
Sep 17, 2024In this paper, we evaluate the creative fiction writing abilities of a fine-tuned small language model (SLM), BART Large, and compare its performance to humans and two large language models (LLMs): GPT-3.5 and GPT-4o. Our evaluation consists of two experiments: (i) a human evaluation where readers assess the stories generated by the SLM compared to human-written stories, and (ii) a qualitative linguistic analysis comparing the textual characteristics of the stories generated by the different models. In the first experiment, we asked 68 participants to rate short stories generated by the models and humans along dimensions such as grammaticality, relevance, creativity, and attractiveness. BART Large outperformed human writers in most aspects, except creativity, with an overall score of 2.11 compared to 1.85 for human-written texts -- a 14% improvement. In the second experiment, the qualitative analysis revealed that, while GPT-4o exhibited near-perfect internal and external coherence, it tended to produce more predictable narratives, with only 3% of its stories seen as novel. In contrast, 15% of BART's stories were considered novel, indicating a higher degree of creativity despite its smaller model size. This study provides both quantitative and qualitative insights into how model size and fine-tuning influence the balance between creativity, fluency, and coherence in creative writing tasks.
Pron vs Prompt: Can Large Language Models already Challenge a World-Class Fiction Author at Creative Text Writing?
Jul 01, 2024It has become routine to report research results where Large Language Models (LLMs) outperform average humans in a wide range of language-related tasks, and creative text writing is no exception. It seems natural, then, to raise the bid: Are LLMs ready to compete in creative writing skills with a top (rather than average) novelist? To provide an initial answer for this question, we have carried out a contest between Patricio Pron (an awarded novelist, considered one of the best of his generation) and GPT-4 (one of the top performing LLMs), in the spirit of AI-human duels such as DeepBlue vs Kasparov and AlphaGo vs Lee Sidol. We asked Pron and GPT-4 to provide thirty titles each, and then to write short stories for both their titles and their opponent's. Then, we prepared an evaluation rubric inspired by Boden's definition of creativity, and we collected 5,400 manual assessments provided by literature critics and scholars. The results of our experimentation indicate that LLMs are still far from challenging a top human creative writer, and that reaching such level of autonomous creative writing skills probably cannot be reached simply with larger language models.
Automatic Scansion of Spanish Poetry without Syllabification
Dec 23, 2020In recent years, several systems of automated metric analysis of Spanish poetry have emerged. These systems rely on complex methods of syllabification and stress assignment, which use PoS-tagging libraries, whose computational cost is high. This cost increases with the calculation of metric ambiguities. Furthermore, they do not consider determining issues in syllabic count such as the phenomena of compensation between hemistichs of verses of more than eleven syllables. However, it is possible to carry out an informative and accurate metric analysis without using these costly methods. We propose an algorithm that performs accurate scansion (number of syllables, stress pattern and type of verse) without syllabification. It addresses metric ambiguities and takes into account the hemistichs compensation. Our algorithm outperforms the current state of the art by 2% in fixed-metre poetry, and 25% in mixed-metre poetry. It also runs 21 and 25 times faster, respectively. Finally, a desktop application is offered as a tool for researchers of Spanish poetry.
An Effectiveness Metric for Ordinal Classification: Formal Properties and Experimental Results
Jun 01, 2020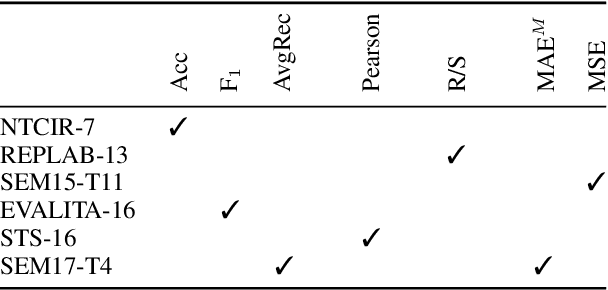
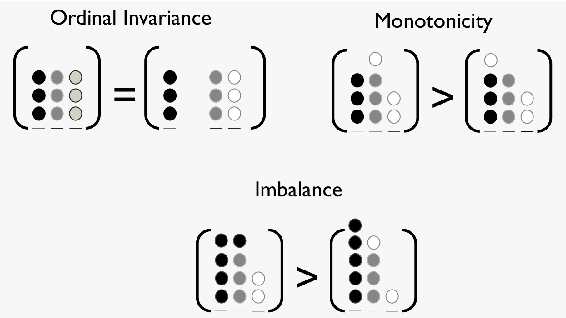
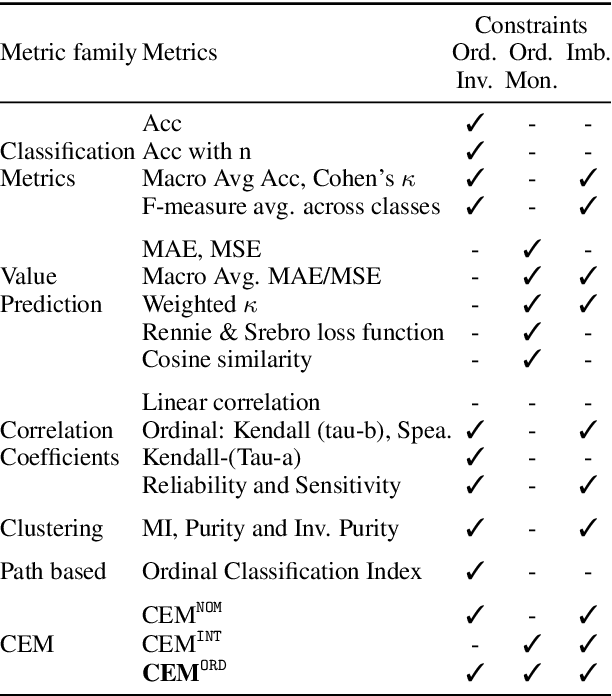
In Ordinal Classification tasks, items have to be assigned to classes that have a relative ordering, such as positive, neutral, negative in sentiment analysis. Remarkably, the most popular evaluation metrics for ordinal classification tasks either ignore relevant information (for instance, precision/recall on each of the classes ignores their relative ordering) or assume additional information (for instance, Mean Average Error assumes absolute distances between classes). In this paper we propose a new metric for Ordinal Classification, Closeness Evaluation Measure, that is rooted on Measurement Theory and Information Theory. Our theoretical analysis and experimental results over both synthetic data and data from NLP shared tasks indicate that the proposed metric captures quality aspects from different traditional tasks simultaneously. In addition, it generalizes some popular classification (nominal scale) and error minimization (interval scale) metrics, depending on the measurement scale in which it is instantiated.
Combining Evaluation Metrics via the Unanimous Improvement Ratio and its Application to Clustering Tasks
Jan 18, 2014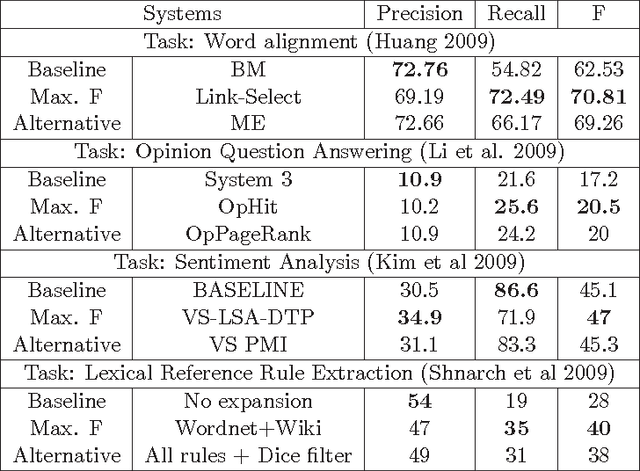
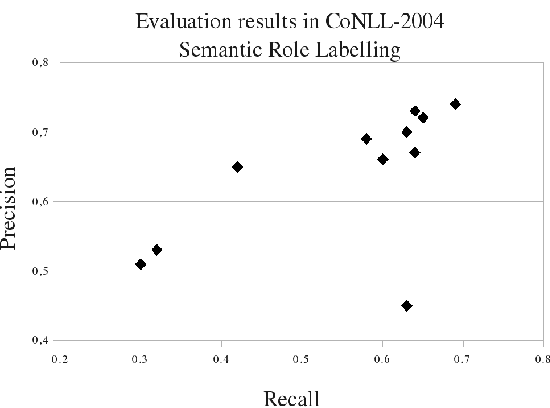
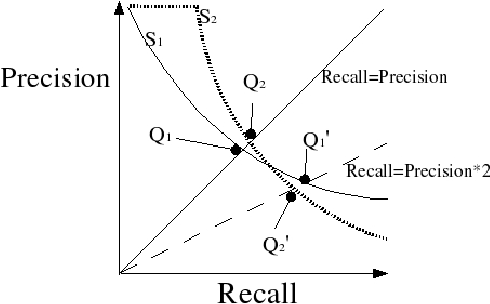
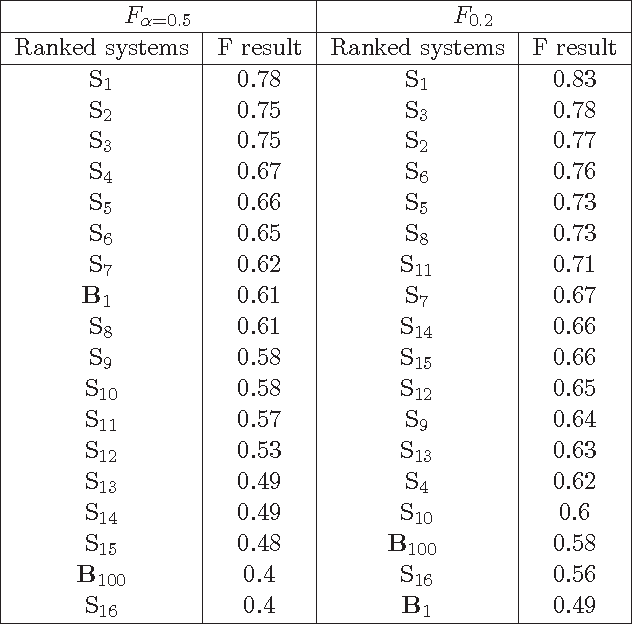
Many Artificial Intelligence tasks cannot be evaluated with a single quality criterion and some sort of weighted combination is needed to provide system rankings. A problem of weighted combination measures is that slight changes in the relative weights may produce substantial changes in the system rankings. This paper introduces the Unanimous Improvement Ratio (UIR), a measure that complements standard metric combination criteria (such as van Rijsbergen's F-measure) and indicates how robust the measured differences are to changes in the relative weights of the individual metrics. UIR is meant to elucidate whether a perceived difference between two systems is an artifact of how individual metrics are weighted. Besides discussing the theoretical foundations of UIR, this paper presents empirical results that confirm the validity and usefulness of the metric for the Text Clustering problem, where there is a tradeoff between precision and recall based metrics and results are particularly sensitive to the weighting scheme used to combine them. Remarkably, our experiments show that UIR can be used as a predictor of how well differences between systems measured on a given test bed will also hold in a different test bed.
Towards Real-Time Summarization of Scheduled Events from Twitter Streams
Apr 17, 2012

This paper explores the real-time summarization of scheduled events such as soccer games from torrential flows of Twitter streams. We propose and evaluate an approach that substantially shrinks the stream of tweets in real-time, and consists of two steps: (i) sub-event detection, which determines if something new has occurred, and (ii) tweet selection, which picks a representative tweet to describe each sub-event. We compare the summaries generated in three languages for all the soccer games in "Copa America 2011" to reference live reports offered by Yahoo! Sports journalists. We show that simple text analysis methods which do not involve external knowledge lead to summaries that cover 84% of the sub-events on average, and 100% of key types of sub-events (such as goals in soccer). Our approach should be straightforwardly applicable to other kinds of scheduled events such as other sports, award ceremonies, keynote talks, TV shows, etc.
The Uned systems at Senseval-2
Oct 28, 2009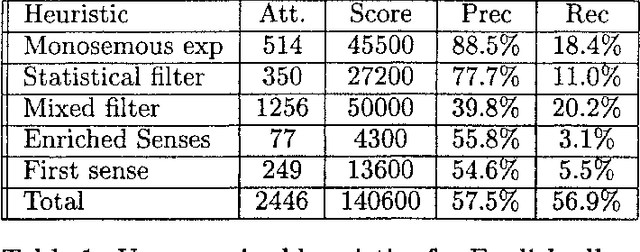
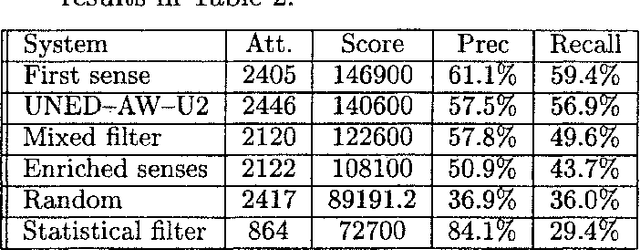
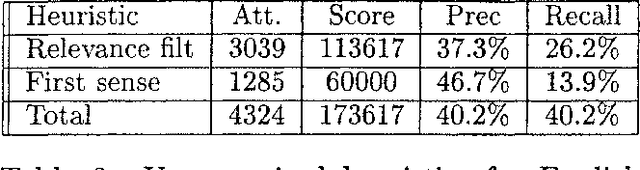
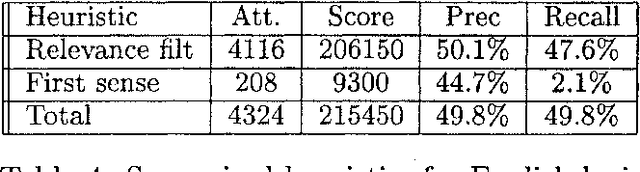
We have participated in the SENSEVAL-2 English tasks (all words and lexical sample) with an unsupervised system based on mutual information measured over a large corpus (277 million words) and some additional heuristics. A supervised extension of the system was also presented to the lexical sample task. Our system scored first among unsupervised systems in both tasks: 56.9% recall in all words, 40.2% in lexical sample. This is slightly worse than the first sense heuristic for all words and 3.6% better for the lexical sample, a strong indication that unsupervised Word Sense Disambiguation remains being a strong challenge.
* latex2e, 5 pages, appeared in SENSEVAL-2, held with ACL-02